星辰与代码:DeepSeek的发展历程
梦开始的地方
2023年7月17日,幻方量化注册成立了DeepSeek,其全称为“杭州深度求索人工智能基础技术研究有限公司,总部位于杭州。它的核心团队来自,其前身中国领先的量化投资机构——幻方量化
创始人及团队在量化交易中积累了丰富的深度学习和大数据应用经验,他们最初利用 AI 技术实现股票交易和数据分析。随着全球对大语言模型(LLM)关注度的急剧上升,团队意识到研发通用型大模型对于中文市场及专业领域(如编程、数学等)的重要性
我查了一下资料发现,早在23年4月14日,DeepSeek前身幻方量化在公众号发布文章幻方新征程,宣布将以研究组织的形式投入AGI征程,当时基本除了圈内,几乎没有一点水花

如今看来是有多么超前的眼界和坚定的意志

技术突破阶段
2024 年,DeepSeek 强势开启生态扩张与技术爆发的新纪元,成为全球 AI 领域瞩目的焦点。
年初 1 月,DeepSeek 便以 DeepSeek-MoE 震撼登场,创新性架构设计以仅 60% 的计算量损耗,成功超越 Llama 2-7B 性能,为后续技术突破奠定坚实基础,在模型效率优化上迈出关键一步。
紧接着 2 月,DeepSeekMath 在 MATH 基准测试中表现惊艳,成绩飙升至 51.7%,无限逼近 GPT-4 水平,数学推理能力实现质的飞跃,极大提升了模型在复杂数学问题求解上的可靠性与精准度。
3 月,DeepSeek 布局多模态领域,VL 系列研发正式启动,为后续多模态融合发展埋下伏笔;5 月,经济型 MoE 架构 DeepSeek-V2 重磅推出,其 API 定价仅为 GPT-4 Turbo 的 1%,以超高性价比打破行业价格壁垒,在保持模型高性能的同时,让更多开发者和企业能够轻松使用,迅速扩大了用户群体和应用场景。
步入 6 月,DeepSeek-Coder-V2 横空出世,在编程任务中与 GPT4-Turbo 全面匹敌,助力开发者高效完成代码编写、调试等工作,显著提升编程效率与质量,成为开发者手中的得力工具。

9 月,DeepSeek 再度发力,成功整合 Coder 与 Chat 模型,升级版 DeepSeek V2.5 震撼上线,实现系统融合,进一步优化用户交互体验,让模型在自然语言处理与代码生成等多方面协同工作,为用户提供更加全面、智能的服务。
在这一年里,DeepSeek 凭借一系列技术突破与创新,不仅拓宽了自身生态版图,更推动了整个 AI 行业向低成本、高效率方向发展,为全球 AI 发展注入强劲动力,引领行业迈向新的发展阶段。
多模态与全球化布局
2024 年第四季度至 2025 年第一季度,DeepSeek 以令人惊叹的速度实现了跨越式发展,在 AI 领域掀起了阵阵波澜。
2024 年 11 月,DeepSeek 推出首个推理专用模型 DeepSeek - R1 - Lite。这一创新性举措,犹如在推理模型赛道上按下了加速键,为后续更强大模型的推出奠定了坚实基础,也为专注于推理任务的开发者和研究人员提供了全新且高效的工具。
紧接着在 12 月,DeepSeek 乘胜追击,发布旗舰模型 DeepSeek - V3。该模型基于 2048 块 H800 GPU 集群,历经 55 天的精心打磨完成训练,训练成本约 557.6 万美元。其性能表现卓越,在众多开源模型中脱颖而出,成功超越 Qwen2.5 - 72B 等开源模型,无论是在复杂的知识问答、代码生成,还是多语言处理等任务中,都展现出了顶尖的实力,为开源模型领域树立了新的标杆。
步入 2025 年 1 月,DeepSeek 的发展势头愈发强劲。DeepSeek - R1 开源模型成功实现与 OpenAI o1 正式版性能对齐,这一成果不仅证明了 DeepSeek 在技术研发上的深厚底蕴,更意味着开发者和用户能够在开源的生态下,享受到与行业顶尖水平相当的模型服务。同月,DeepSeek 智能助手强势登顶美区 App Store 榜首,其简洁高效的交互体验、强大精准的回答能力,吸引了全球用户的目光,成为了用户在智能交互领域的首选应用之一。此外,DeepSeek 还推出了多模态系统 Janus - Pro,进一步拓展了 AI 应用的边界,实现了文本、图像、音频等多种信息模态的融合处理,为用户带来了更加丰富多元的交互体验。
到了 2025 年 2 月,在经过一段时间的市场验证,收集大量用户反馈并进行深度分析后,DeepSeek 对 API 定价策略做出调整。输入 token 价格上调 100%,输出 token 价格上调 300%。此次价格调整,是基于模型性能提升、服务优化以及市场供需等多方面因素综合考量的结果,旨在为用户持续提供高质量、稳定且不断进化的 AI 服务,同时也确保 DeepSeek 在技术研发与市场运营之间找到良好的平衡,以推动自身在 AI 领域的持续创新与发展。
在这短短几个月的时间里,DeepSeek 凭借一系列具有开创性的成果,展示了其在 AI 领域的强大实力与无限潜力,也为整个行业的发展注入了新的活力与动力。
DeepSeek模型发展
另外DeepSeek 系列在技术创新的道路上也是不断发展,从最初的DeepSeek LLM、DeepSeekMoE、DeepSeekMath,再到DeepSeek V2、DeepSeek V3 以及最新的 DeepSeek R1

DeepSeek LLM
DeepSeek LLM 属于密集的LLM模型,沿用了 LLaMA 的部分设计,如采用Pre-Norm结构、RMSNorm函数、SwiGLU激活函数和Rotary Embedding位置编码。
关键技术 :
- 基于 Transformer 架构,采用分组查询注意力(GQA)优化推理成本。
- 支持多步学习率调度器,提升训练效率。
- 在预训练和对齐(监督微调与 DPO)方面进行了创新。
- 缩放定律研究 :提出了新的最优模型/数据扩展-缩放分配策略。
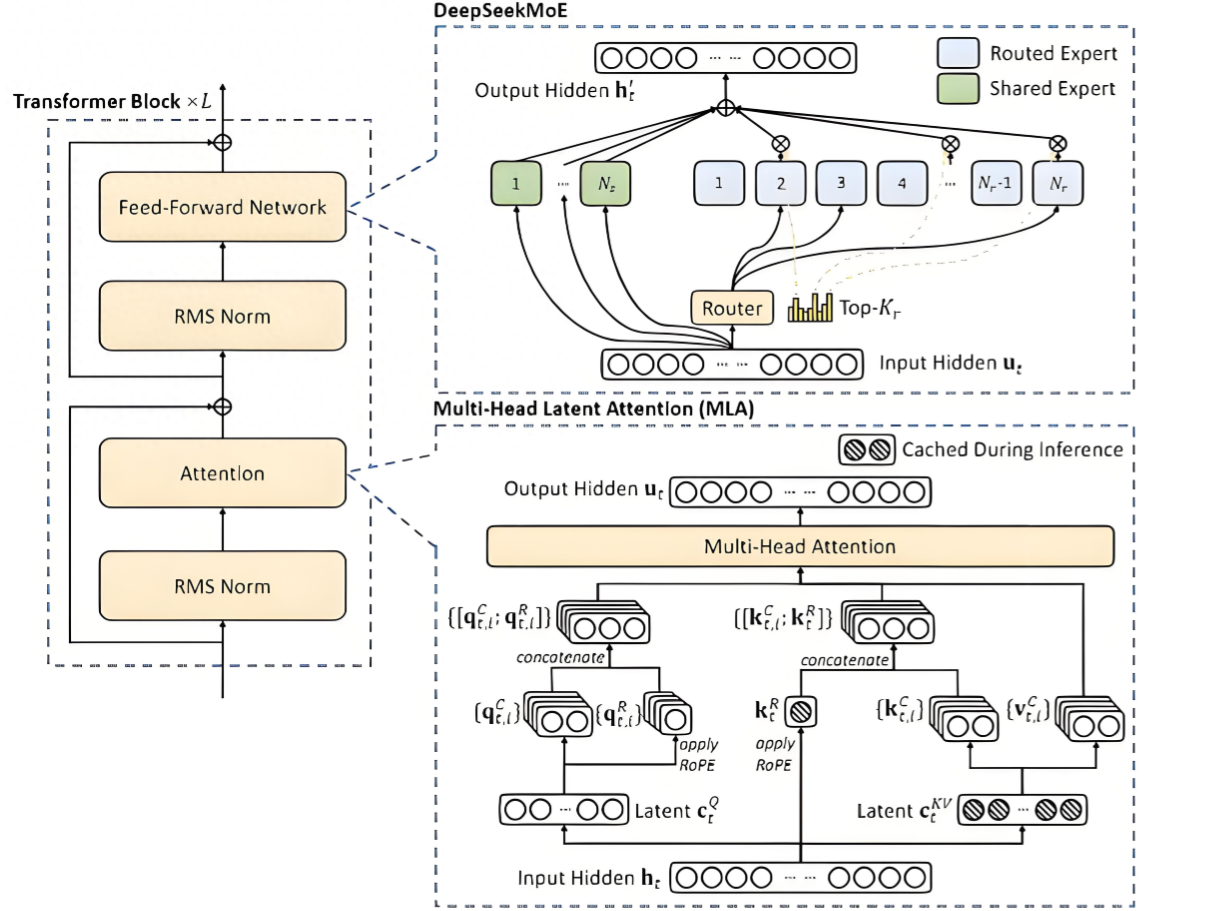
DeepSeek MoE
DeepSeekMoE 是一种创新的MoE架构,专门设计用于实现终极专家专业化(expert specialization)。
关键技术 :
- 细粒度专家分割 (Fine-Grained Expert Segmentation):将专家细分为更细的粒度,以实现更高的专家专业化和更准确的知识获取。
- 共享专家隔离 (Shared Expert Isolation):隔离一些共享专家以减轻路由专家之间的知识冗余。
- 负载均衡的辅助损失 (Auxiliary Loss for Load Balance):通过专家级平衡损失和设备级平衡损失,缓解模型训练时可能出现负载不均衡问题。
DeepSeek Math
DeepSeekMath 是数学推理模型。
关键技术 :
- 数学预训练:代码训练可提升数学推理能力。
- 监督微调:构建多格式数学指令微调数据集。
- 强化学习:提出 GRPO(Group Relative Policy Optimization)算法,通过组分数估计基线,减少训练资源消耗。
DeepSeek V2
DeepSeek V2 是一款 经济高效的大规模MoE模型,优化推理与训练成本。
关键技术:
- DeepseekMoE :把 FFN 的结构改成 DeepseekMoE,是对传统 MoE 结构的改进。
- 多头潜在注意力(MLA):利用低秩键值联合压缩,来降低推理时的KV缓存开销。
- 多Token预测(MTP):预测多步依赖,加速推理生成。
- 无辅助损失的负载均衡策略 :引入专家级均衡损失,设备级平衡损失,通信平衡损失,避免负载均衡带来的辅助损失。
DeepSeek V3
整体思路: 基于DeepSeek-V2,引入新的架构和训练策略,进一步提升模型的性能,同时降低训练成本。在模型架构、训练方法、知识蒸馏与能力提升、模型性能与成本等方面进行创新。
关键技术:
- 无辅助损失的负载均衡策略 (ALFLB): 通过引入偏置项动态调整专家负载。
- Token预测 训练目标(MTP): 在每个位置预测多个未来的 token,提高模型的数据效率。
- 高效的训练框架:FP8 混合精度训练框架,通过 DualPipe 算法和优化的通信内核,实现了近乎零开销的跨节点通信。
- 知识蒸馏 :从 DeepSeek - R1 系列模型中蒸馏推理能力,将其融入 DeepSeek - V3,提升了模型的推理性能。
DeepSeek R1
定位:强化学习驱动的推理模型,颠覆传统训练流程。
关键技术:
- 零监督微调(Zero-SFT):完全依赖强化学习(RL),成本降至OpenAI O1的3%-5%18。
- 组相对策略优化(GRPO):替代PPO算法,无需价值模型,降低计算开销89。
- 双重奖励系统:结合准确性奖励与格式奖励,提升结构化输出能力8。
时代的需求
在当下,中美技术竞争态势愈发激烈,美国对芯片出口实施严格限制,这使得国内在大模型技术领域突破国外垄断的需求迫在眉睫。在此关键节点,DeepSeek团队毅然选择成立一家独立的人工智能基础技术研究公司。其目光聚焦于低成本、高性能模型的研发,这一举措意义非凡。
一方面,它能够充分满足国内市场对契合中文语境的AI需求,为国内用户带来更贴合使用习惯、更懂中国文化和语言特色的AI服务;另一方面,它也为国产大模型产业树立起标杆,激励更多本土企业投身大模型研发,打破国外技术在该领域的长期主导局面,推动国产大模型产业朝着自主、创新、高效的方向大步迈进 。
从开源社区的“破局者”到AGI赛道的“领跑者”,DeepSeek未来可期!
本文就先到这里啦,最后再次感谢大家的阅读,deepseek介绍基本就到这了,后面我们会讲讲如何具体使用deepseek来为我们学习和工作赋能,下期再见,拜~
点赞收藏在看就是对笔者最好的催更!

作者:小牛呼噜噜
关注公众号:小牛呼噜噜!无需繁琐步骤,无任何套路,只需在后台回复deepseek,精心整理的 DeepSeek 全套资料即刻免费到手,带你轻松解锁 DeepSeek 的奥秘